XPath (XML Path Language) es un lenguaje que permite construir expresiones que recorren y procesan un documento XML. La idea es parecida a las expresiones regulares para seleccionar partes de un texto sin atributos (plain text). XPath permite buscar y seleccionar teniendo en cuenta la estructura jerárquica del XML. XPath fue creado para su uso en el estándar XSLT, en el que se usa para seleccionar y examinar la estructura del documento de entrada de la transformación. XPath fue definido por el consorcio W3C.
Caracteristicas de XPath
- Es una sintaxis para definir partes de un documento XML
- Usa expresiones de ruta para navegar en documentos XML
- Contiene una biblioteca de funciones estándar
- Es un elemento importante en XSLT y en XQuery
- XPath 3.0 es una recomendación de W3C desde Abril de 2014.
Tipos de nodos
Las partes de un documento XLM se denominan nodos. Existen 7 tipos de nodos diferentes:
- Raíz: El nodo raíz o nodo documento (root node) no debe confundirse con el elemento raíz. Éste es más bien el nodo padre virtual del elemento raíz.
- Elemento (element node)
- Atributo (attribute node)
- Texto (text node)
- Espacio de nombres (namespace node)
- Instrucción de procesamiento (processing instruction node)
- Comentario (comment node)
Cada uno de estos nodos puede ser seleccionado con XPath para su posterior procesamiento en XSL.
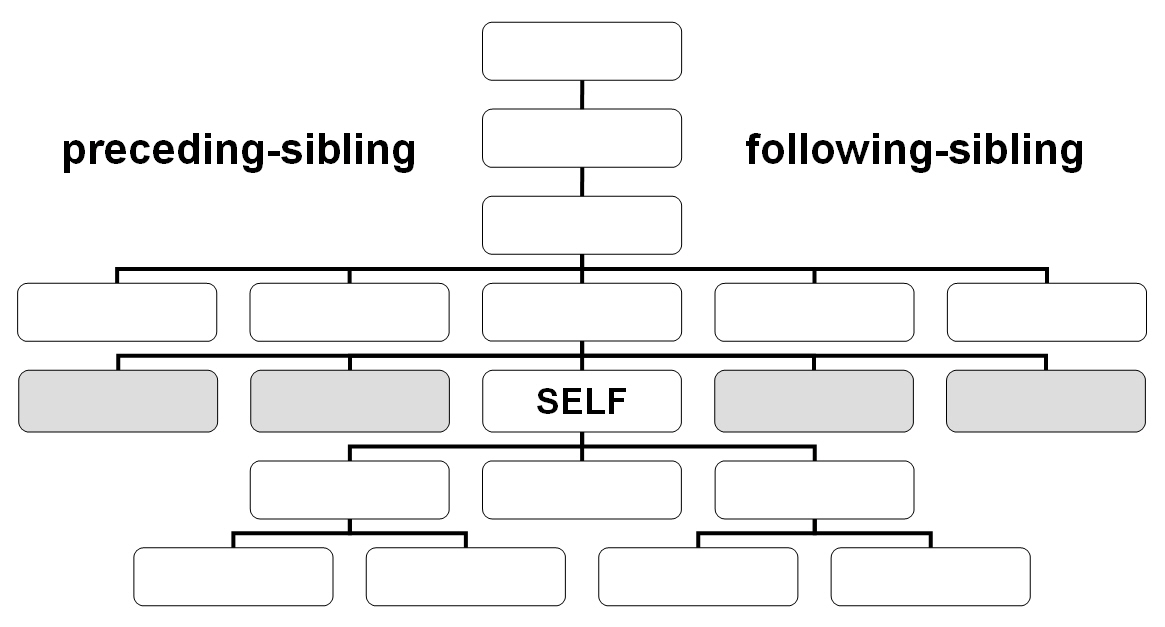
Los ejes
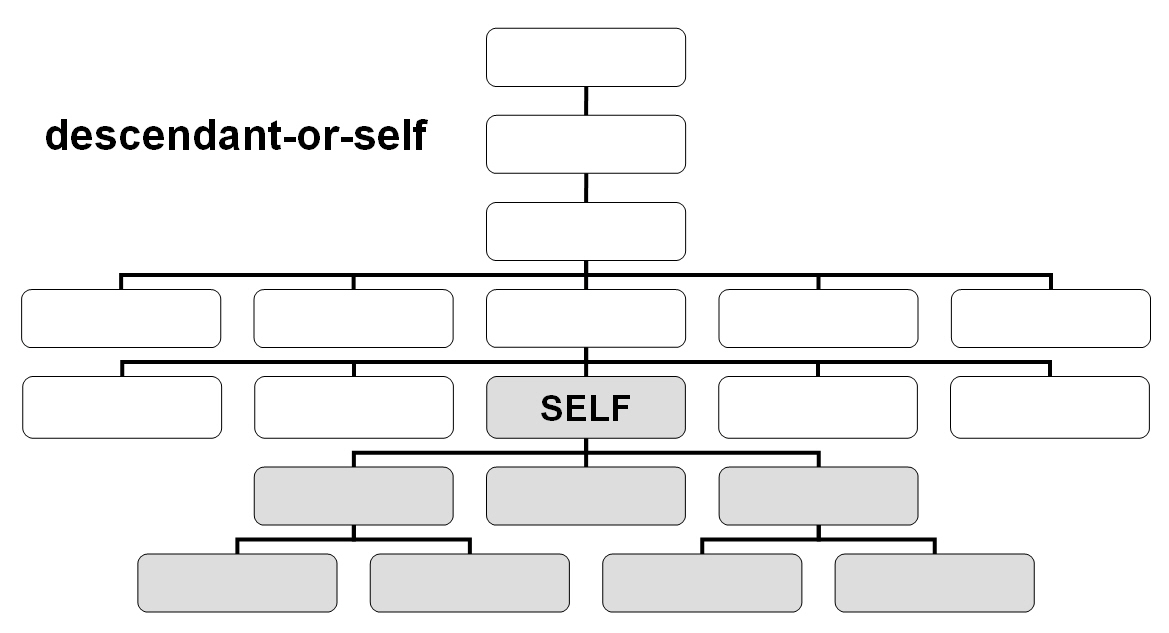
La navegación dentro de un documento XML a través de XPath tiene lugar desde un nodo de contexto, que en las siguientes ilustraciones se representan como 'SELF'. El nodo de contexto es siempre el punto de partida en el que se encuentra el procesador XSLT. Los nombres de los ejes definen las relaciones de parentesco respecto al mismo. En las ilustraciones se muestran 11 de los 13 ejes disponibles. Junto a los ejes que presentamos a continuación, que permiten la navegación en un documento, es posible seleccionar atributos de un nodo o nodos de espacio de nombres a través de los ejes attribute o namespace.
El eje self contiene el nodo de contexto.
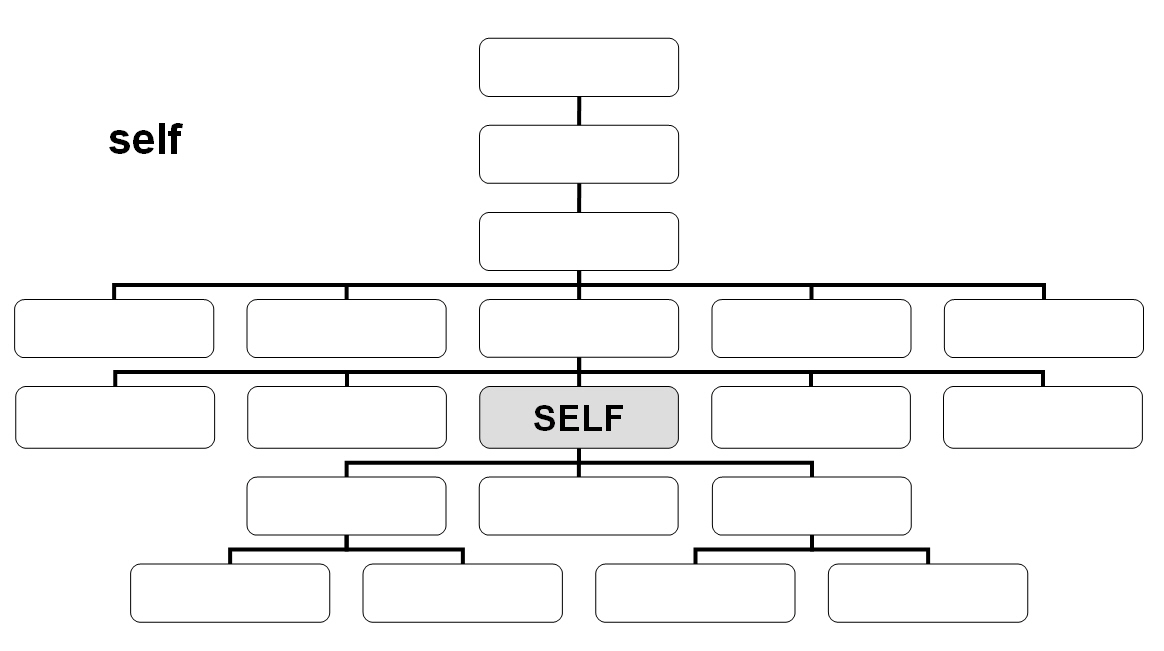
El eje child contiene los nodos hijo del nodo de contexto.
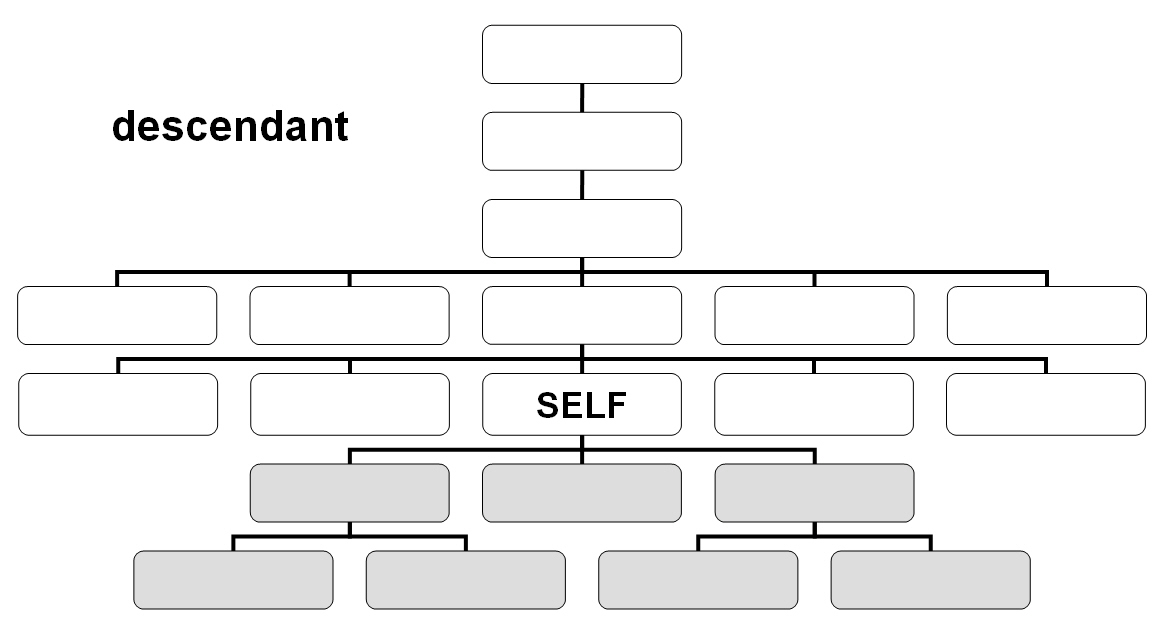
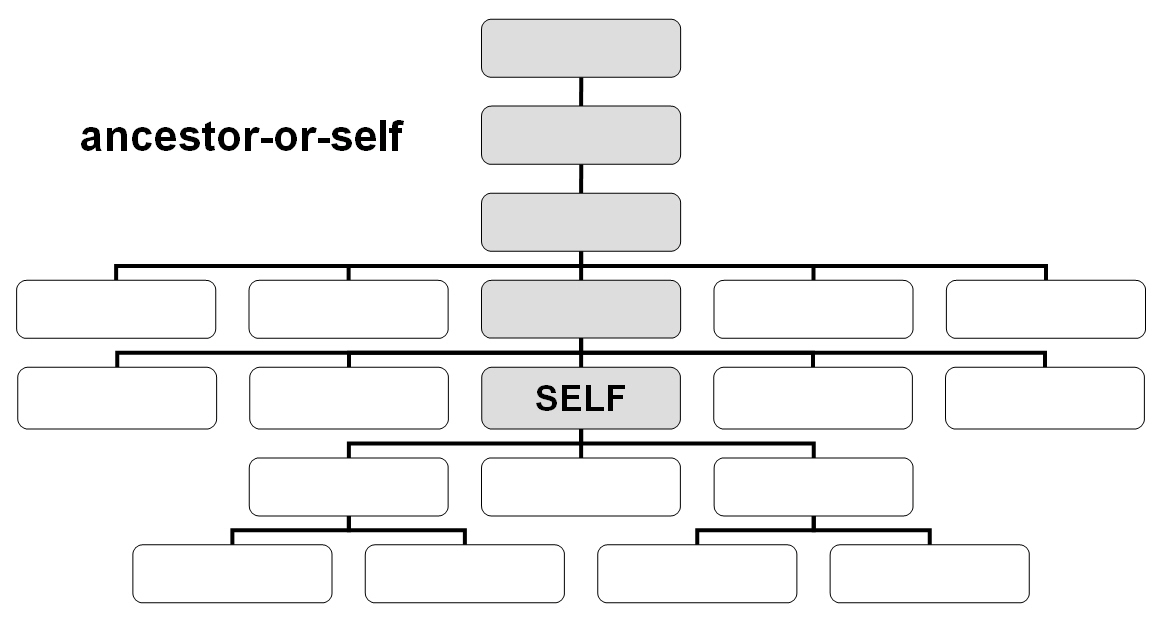
El eje descendant-or-self contiene el nodo de contexto y los descendientes.
El eje parent contiene el padre del nodo de contexto.
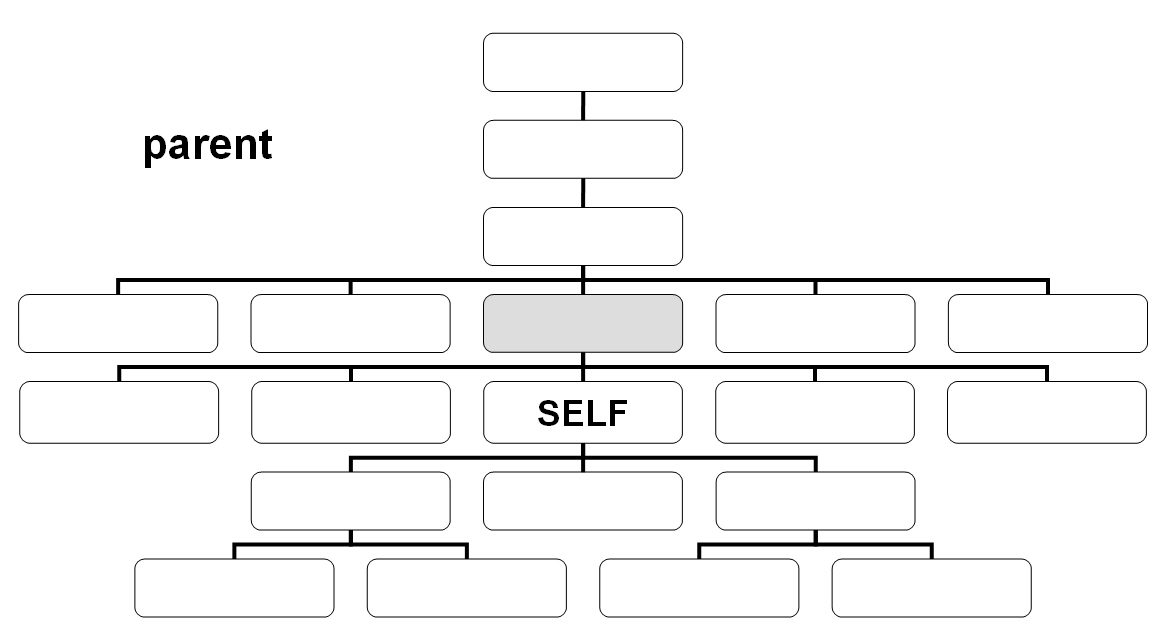
El eje ancestor contiene los ancestros del nodo de contexto.
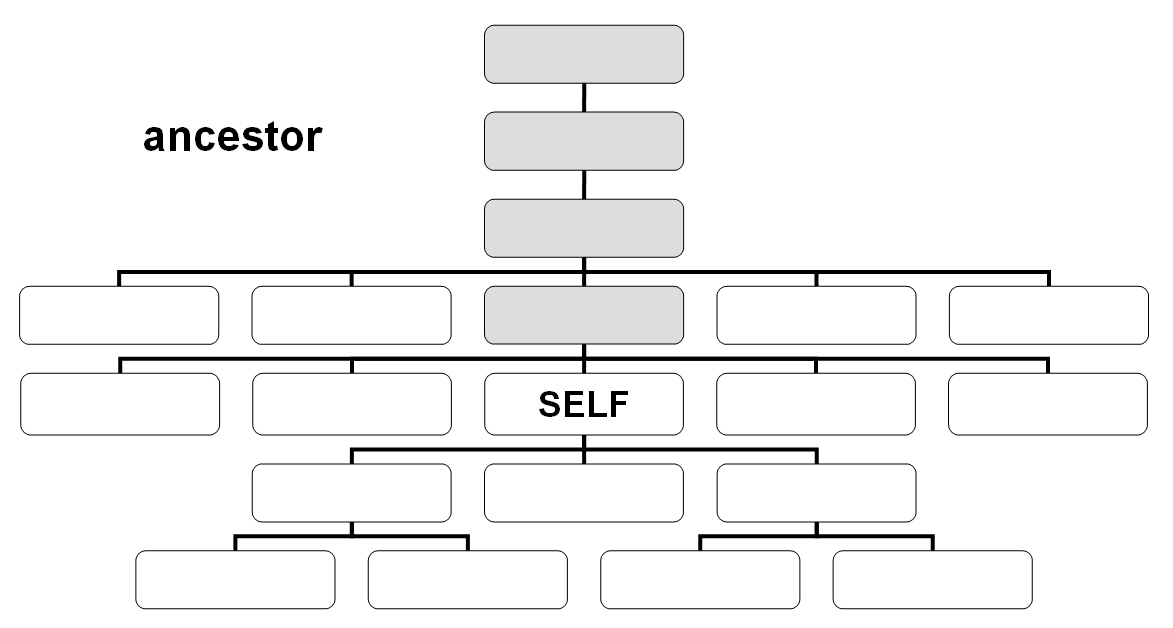
El eje ancestor-or-self contiene el nodo de contexto y sus descendientes.
El eje preceding contiene todos los nodos que aparecen antes del nodo de contexto, excluyendo los ancestros. El eje following contiene todos los nodos que aparecen después del nodo de contexto, excluyendo los descendientes.
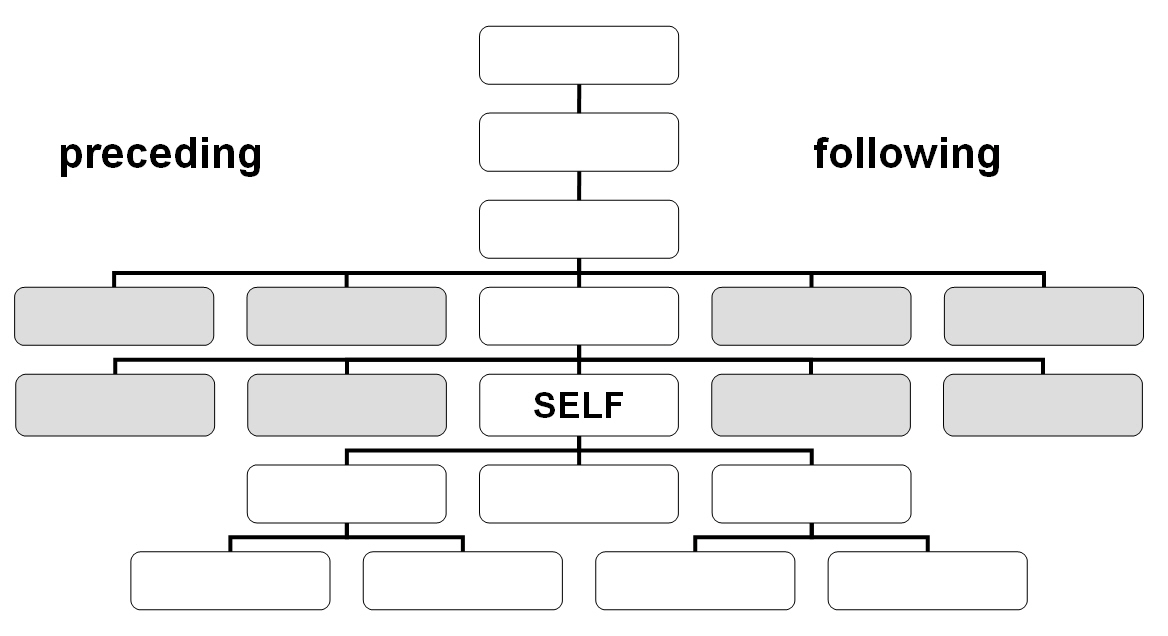
El eje preceding-sibling contiene los hermanos precedentes del nodo de contexto. El eje following-sibling contiene los hermanos situados detrás del nodo de contexto.
Localización
La localización es la expresión que permite al procesador seleccionar nodos o un conjunto de nodos. Esta localización se conoce como camino o ruta de localización y puede presentar diversas formas:
- con sintaxis abreviada o completa
- como ruta de localización relativa o absoluta.
Sintaxis abreviada o completa
En XPath existen dos formas de sintaxis, que en la práctica se pueden utilizar de manera combinada. La sintaxis abreviada se usa normalmente cuando se trata de nodos y ejes que son seleccionados con mucha frecuencia, mientras que la sintaxis completa se utiliza en caso de nodos y ejes a los que se accede con menor frecuencia. En los siguientes apartados se utilizará la sintaxis completa, recurriendo a la sintaxis abreviada cuando se trate de expresiones más frecuentes.
- Un ejemplo de sintaxis completa:
/child::libro/child::autor/child::nombre/attribut::apellido- En sintaxis abreviada:
/libro/autor/nombre/@apellidoEn la sintaxis abreviada se prescinde del nombre del eje child:: y el atributo se introduce anteponiendo el carácter @. En los próximos ejemplos se ofrecerán más detalles sobre la sintaxis abreviada.
Equivalencias entre sintaxis completa y abreviada
| Sintaxis completa | Sintaxis abreviada |
|---|---|
child:: |
Eje por defecto. Se puede omitir. |
attribute:: |
@ |
descendant-or-self::node()/ |
// |
self::node() |
. |
parent::node() |
.. |
Rutas relativas y absolutas
La ruta de localización XPath puede ser relativa o absoluta. Una ruta absoluta comienza por el nodo raíz, que es el nodo situado directamente sobre el elemento raíz. Esta distinción es necesaria, ya que desde el elemento raíz no sería posible acceder, por ejemplo, a comentarios o instrucciones que se encuentran fuera del mismo.
Las rutas de localización constan de pasos de localización separados por /.
Un ejemplo:
/child::Europa/child::pais/child::nombreEn este caso se trata de una ruta absoluta que parte del nodo raíz. El nodo raíz se indica mediante una barra diagonal. Desde ahí se selecciona el elemento raíz <Europa>. La expresión generará un resultado si el elemento raíz tiene un nodo hijo <pais> y éste a su vez contiene un nodo hijo <nombre>. Los ejes se definen mediante el nombre del eje seguido de dos signos de dos puntos. En el caso del eje child, puede omitirse la expresión child::. Así, la ruta de localización Europa/pais/nombre equivale a la ruta del ejemplo con sintaxis abreviada. Por el contrario, las rutas de localización relativas necesitan un nodo de contexto. La ruta se evaluará desde esta posición.
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="style.xsl"?>
<Europa>
<pais>
<nombre>Alemania</nombre>
<habitantes unidad="millones">82.4</habitantes>
<capital>Berlín</capital>
<sigla-pais>D</sigla-pais>
<prefijo>0049</prefijo>
</pais>
<pais>
<nombre>Francia</nombre>
<habitantes unidad="millones">58.5</habitantes>
<capital>Paris</capital>
<sigla-pais>F</sigla-pais>
<prefijo>0033</prefijo>
</pais>
<pais>
<nombre>España</nombre>
<habitantes unidad="millones">39.4</habitantes>
<capital>Madrid</capital>
<sigla-pais>E</sigla-pais>
<prefijo>0034</prefijo>
</pais>
</Europa> Ejemplo:
child::pais/child::nombreDe igual forma que en la ruta absoluta, en este caso se generará un resultado si el nodo de contexto tiene un nodo hijo <pais>, que a su vez posee un nodo hijo <nombre>.
La descripción aquí presentada de las rutas relativas es incompleta. Podrá encontrar más información sobre rutas relativas en literatura especializada sobre XPath.
Las siguientes son expresiones XPath con sintaxis abreviadas y extendidas. ¿Qué mostrarían estas consultas?
/Europa/pais/nombre
/Europa/pais/habitantes
/Europa/descendant::habitantes
/Europa/pais/nombre/following-sibling::habitantes
/Europa/pais/nombre/following-sibling::habitantes/parent::pais/descendant::capitalLas expresiones XPath sirven para la selección de nodos en un árbol XML. Gracias al filtrado de expresiones a través de predicados, es posible usar expresiones XPath para seleccionar grupos de nodos que respondan a criterios más complejos, definiendo el acceso a los nodos de una manera mucho más precisa. Los predicados son expresiones que devuelven un resultado booleano (verdadero o falso), de manera que se puede filtrar de nuevo el resultado del nodo seleccionado a través de la expresión XPath. En caso de que un determinado nodo dentro de un conjunto de nodos se corresponda con el predicado de la expresión (que se cumpla la condición del mismo), éste pasará a formar parte del resultado. Por el contrario, si la condición no se cumple, se excluirá el nodo del resultado. De esta forma es posible afinar la búsqueda dentro de un determinado conjunto inicial de nodos a través de las restricciones realizadas mediante predicados.
Localización de distintos tipos de nodos
Hasta ahora nos hemos ocupado sobre todo con los nodos elemento. No obstante, existen otros tipos de nodo que pueden ser seleccionados para su posterior análisis y procesamiento. La siguiente tabla muestra ejemplos de cómo se realiza tal selección.
nombre/text() |
En caso de que se quiera acceder al nodo de texto del elemento nombre se deberá usar la prueba de nodo text(). |
direccion/comment() |
En caso de que se quiera acceder al nodo de comentario del elemento direccion se deberá usar la prueba de nodo coment(). |
dirección/node() |
Si se quiere acceder a todos los tipos de nodos (con excepción de los atributos) se deberá usar la prueba de nodo node(). |
Ejemplo:
//direccion[localidad="Stuttgart"]La expresión //direccion selecciona todos los nodos elemento "direccion" del documento. En el segundo paso se reduce esta selección mediante un predicado. Sólo aquellos elementos que tengan un elemento hijo "localidad" y que el valor del mismo sea "Stuttgart" permanecerán en la selección. Los demás serán excluidos.
Es posible, además de la comparación de cadenas, restringir la selección mediante la comparación de otros valores en la expresión de un predicado. Por ejemplo:
| Comparación de cadena | direccion[nombre="Pepe López"] |
| Comparación numérica (mayor) | disco[@calificacion > 3] |
| Comparación numérica (menor o igual) | //cancion[@año <= 1990] |
| Combinación de "mayor" y "no igual a" | disco[@calificacion < 2]/cancion[@año != 2000] |
Además de la comparación de valores, es posible establecer la coexistencia de otros elementos como criterio para analizar un conjunto de nodos.
/listadedirecciones[direccion] |
Comprueba si existe el elemento hijo "dirección". |
/listadedirecciones/direccion[@cat] |
Comprueba si existe un atributo "cat" dentro de "direccion". |
Atención: Un predicado sólo comprueba si la condición es veradera o falsa. Se trata de una conversión implícita a un valor booleano.
Operadores booleanos en predicados
Los predicados pueden contener los operadores booleanos "and" y "or".
//titulo[@estilo="pop" and @calificacion=4] |
Selecciona todos los elementos "titulo" que posean un atributo "estilo" con el valor "pop" y además un atributo "calificacion" con el valor 4. |
//titulo[@estilo="pop" or @calificacion> 2] |
Selecciona todos los elementos "titulo" que posean un atributo "estilo" con el valor "pop" o un atributo "calificacion" cuyo valor sea mayor que 2. |
Predicados en cascada
Además del filtrado mediante operadores booleanos, es posible restringir la selección mediante una disposición en serie de predicados. Los predicados en cascada funcionan como una superposición de filtros. En primer lugar se filtra un conjunto de nodos, que será a su vez el conjunto de partida para el segundo predicado, etc.
//seccion[parrafo][@tipo='advertencia']En primer lugar se seleccionan todos los elementos seccion. El primer predicado reduce la selección a aquellos elementos que tengan un elemento hijo "parrafo". El conjunto resultante se filtra de nuevo mediante el segundo predicado, de manera que sólo quedaran los elementos que tengan un atributo "tipo" con el valor "advertencia".
Unión de conjuntos de nodos
Hasta ahora se ha definido en cada expresión sólo un conjunto de nodos. No obstante, se dan con frecuencia aplicaciones en las que se deben unir varios conjuntos de nodos. En el ejemplo ofrecido a continuación se selecciónan todos los títulos dentro del estilo pop y todas las compañías discográficas.
//titulo[@estilo="pop"] | //discograficaFunciones XPath
Las funciones ofrecen operaciones avanzadas adicionales en la consulta de conjuntos de nodos, así como en el análisis de cadena de nodos de texto y valores de atributos. Las funciones XPath se pueden usar en expresiones XPath y en predicados, tal como se muestra en el siguiente ejemplo:
count(//cancion)
//disco[count(cancion)>10]Las funciones pueden contener un argumento y devuelven siempre un valor. En el primer ejemplo la función "count" tiene como argumento un conjunto de nodos y devuelve como valor de salida un conjunto de nodos.
Ejemplos de funciones de conjuntos de nodos:
local-name(..) |
Devuelve el nombre del elemento padre como cadena. |
//cancion[position()=5] (Sintaxis abreviada [5] ) |
Devuelve todas las canciones que ocupen la quinta posición en cada disco. |
//cancion[position()=last()] |
Devuelve las canciones que ocupen la última posición en cada disco. |
Ejemplos de funciones de cadena:
//disco[string-length(titulo) > 20 ] |
Selecciona todos los discos cuyo título tenga más de 20 caracteres. |
//disco[starts-with(interprete,'M')] |
Selecciona todos los discos en los que el nombre del intérprete comience con la letra "M". |
Un ejemplo de una función muy útil y usada con mucha frecuencia es "not()". Esta función niega una expresión booleana. A continuación se ofrece un ejemplo del empleo de esta función:
//disco[not(cancion)] |
Selecciona todos los discos que no tengan un elemento "cancion". |
Camino de acceso a los datos de acceso a un árbol XML